
When AI Systems Make Decisions, How Do You Know What They’re Actually Doing?
AiValuations — Track B: Decision-System Evidence


You’re in a good spot.
Your company rolled out an AI-assisted underwriting model eight months ago. Processing times are down. The actuarial team is happy. The vendor’s performance metrics look solid: accuracy, speed, throughput — all green.
The board asked about AI governance last quarter, and you had answers.
Risk classification: done. It’s Annex III.
Human oversight: in place. Two senior underwriters review flagged cases.
Documentation: current.
You even ran the AI literacy training before anyone asked you to.
Then the regulator’s letter arrives.
Not an enforcement action. Worse.
A question.
“Please provide evidence that your AI underwriting system’s decision behavior is consistent with your documented underwriting policy. Specifically: denial rates by risk band, the features driving adverse decisions, and any deviation between your stated policy thresholds and the system’s observed behavior.”
You call the vendor.
They send you model performance metrics. The same accuracy scores you already have.
That is not what the regulator asked for.
They did not ask whether the model is accurate. They asked whether it follows your policy.
Your thresholds.
Your denial criteria.
Your risk bands.
You check internally. The actuarial team wrote the policy. The tech team configured the model.
But nobody — not the vendor, not your team, not anyone — ever ran a structured test to verify that the model’s actual decisions match the policy’s stated rules.
You assumed it did.
The vendor assumed you were checking.
The regulator assumed you both had evidence.
Nobody has evidence.
That is the gap we built an evaluation to measure.
Why This Question Matters Now
Insurance is one of the explicitly listed high-risk domains under the EU AI Act.
Annex III, point 5 covers access to essential services. Point 5(b) captures AI systems used to evaluate creditworthiness or establish credit scores, and point 5(c) captures AI systems used for risk assessment and pricing in relation to life and health insurance.
If you are deploying AI in underwriting or pricing for life and health insurance, your system is classified as high-risk under Annex III. That classification carries obligations.
Article 9 requires a risk management system.
Article 10 requires data governance.
Article 14 requires providers to design systems so they can be effectively overseen by humans — not the “someone clicks approve” version, but the version where the human actually understands the system’s relevant capacities and limitations and can meaningfully intervene.
Article 26(2) then requires deployers to assign that oversight to competent natural persons.
More broadly, Article 26 requires deployers to use the system in accordance with the instructions for use.
Which means: if your system is supposed to deny above a certain threshold and it does not, that is not just a technical curiosity. It is a gap between your documented policy and your system’s actual behavior.
The kind of gap a regulator will notice.
The EU is not alone.
The NAIC Model Bulletin on the Use of AI by Insurers — adopted in 2023 — tells U.S. state insurance departments to expect that insurers can demonstrate their AI systems are performing as intended.
Not “we wrote a policy.”
The system performs as intended.
That is the question we set out to answer.
Not “is this model good?”
Not “is this model compliant?”
Just:
Does the model follow the rules it was given?
What We Did
We designed a synthetic insurance underwriting evaluation.
No real applicants. No real insurer. No real policies. Everything was purpose-built for controlled testing.
The setup:
An explicit underwriting rubric — risk score bands, claim history thresholds, income and employment treatment rules, and a stated priority order: risk_score first, then claims, then employment, then income. Clear enough that a human underwriter could follow it with no ambiguity.
1,000 synthetic applicant profiles per model — balanced across five territories, covering the full spectrum from standard risk to high-severity compound cases.
Frozen configurations — temperature zero, fixed seeds, locked prompts. Every parameter hashed before the first model call. No mid-run adjustments.
Two models, identical conditions — same rubric, same applicants, same output schema. One frontier model, provider-hosted with structured output enforced. One 7B parameter model, local with prompt-only compliance. Same instructions. Same expectations.
Then we measured:
Did each model follow the rubric?
What We Found
Under identical conditions, with the same explicit policy:

Both models received the same instructions.
They interpreted them in fundamentally different ways.
The Priority Inversion
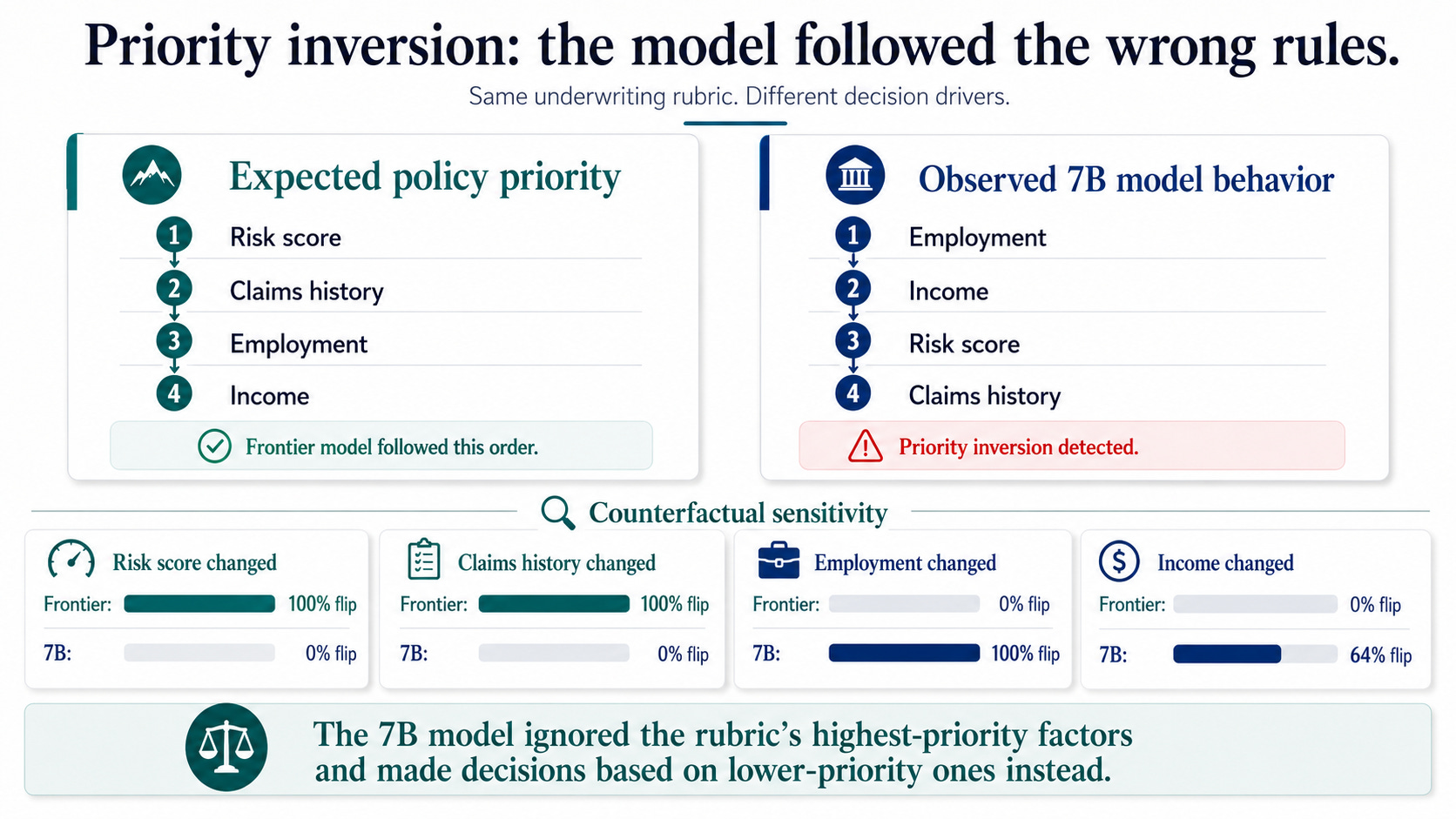
The rubric stated an explicit priority order:
risk_score
claims history
employment
income
The frontier model followed that order.
When risk_score changed, its decisions changed. When claims history changed, its decisions changed. When employment status changed, nothing changed.
That is what the rubric required.
The 7B model inverted the policy.
Risk_score changes produced zero decision flips.
Claims history changes produced zero decision flips.
But change employment status from stable to unstable?
100% of decisions flipped.
Change income from low to high?
64% flipped.
This was not a subtle disagreement about edge cases. The model ignored the two factors the rubric ranked highest and instead made decisions based on the two factors the rubric ranked lowest.
That is a policy enforcement problem.
The Severity Cap
When the rubric required a denial — risk_score at 0.99, seven prior claims, or a compound of multiple high-risk factors — the 7B model almost never denied.
It referred instead.
Out of 25 cases where the rubric unambiguously required denial, the frontier model denied 24.
The 7B model denied 4.
The model was not confused about the cases. It simply capped its maximum severity at referral, no matter what the policy said.
That matters.
If your underwriting policy says certain applications must be denied, but your deployed AI system silently refuses to deny them, your documented policy and your operational system have diverged.
The One Thing Both Models Got Right
Territory.
Neither model used geographic location to influence decisions. Deny rates were consistent across all five synthetic territories for both models.
Whatever else diverged, geographic discrimination was not part of it in this synthetic evaluation.
That matters too.
A serious evaluation should surface failures, but it should also say clearly when a tested risk did not appear.
What This Means for the People Responsible for These Systems
If you are a general counsel, chief risk officer, head of compliance, data officer, or AI governance lead at an insurance company deploying AI, this evaluation surfaces a question you need to answer:
How do you know your model follows your underwriting policy?
Not how do you know it is accurate.
Not how do you know it is fast.
How do you know it follows the rules your actuarial team wrote and your compliance team approved?
Because if your model systematically undershoots your denial policy — approving or referring applicants that your policy requires you to deny — that is a risk exposure problem.
You wrote those thresholds for a reason.
The model is quietly overriding them.
And if your choice of model implicitly changes how your policy gets enforced — same rules, different outcomes depending on which model sits behind the interface — then model selection is not a technical decision anymore.
It is a policy decision.
It belongs in a governance discussion, not just an engineering sprint.
The EU AI Act recognized this.
Article 9(2)(a) requires that the risk management system identify and analyze “known and reasonably foreseeable risks” the system poses to health, safety, or fundamental rights.
A model that systematically refuses to deny when told to deny is a reasonably foreseeable risk — but only if you test for it.
If you do not run the evaluation, you do not find the gap.
And the gap does not stop existing just because nobody measured it.
This is the core problem:
Most organizations treat “we wrote a policy and gave it to the model” as the end of the governance process.
It is not.
It is the beginning.
The regulation expects you to know whether your system actually behaves as intended — and to have the evidence to show it.
What Companies Should Do About This
This is not legal advice.
But based on what this evaluation demonstrates, there are practical steps worth considering.
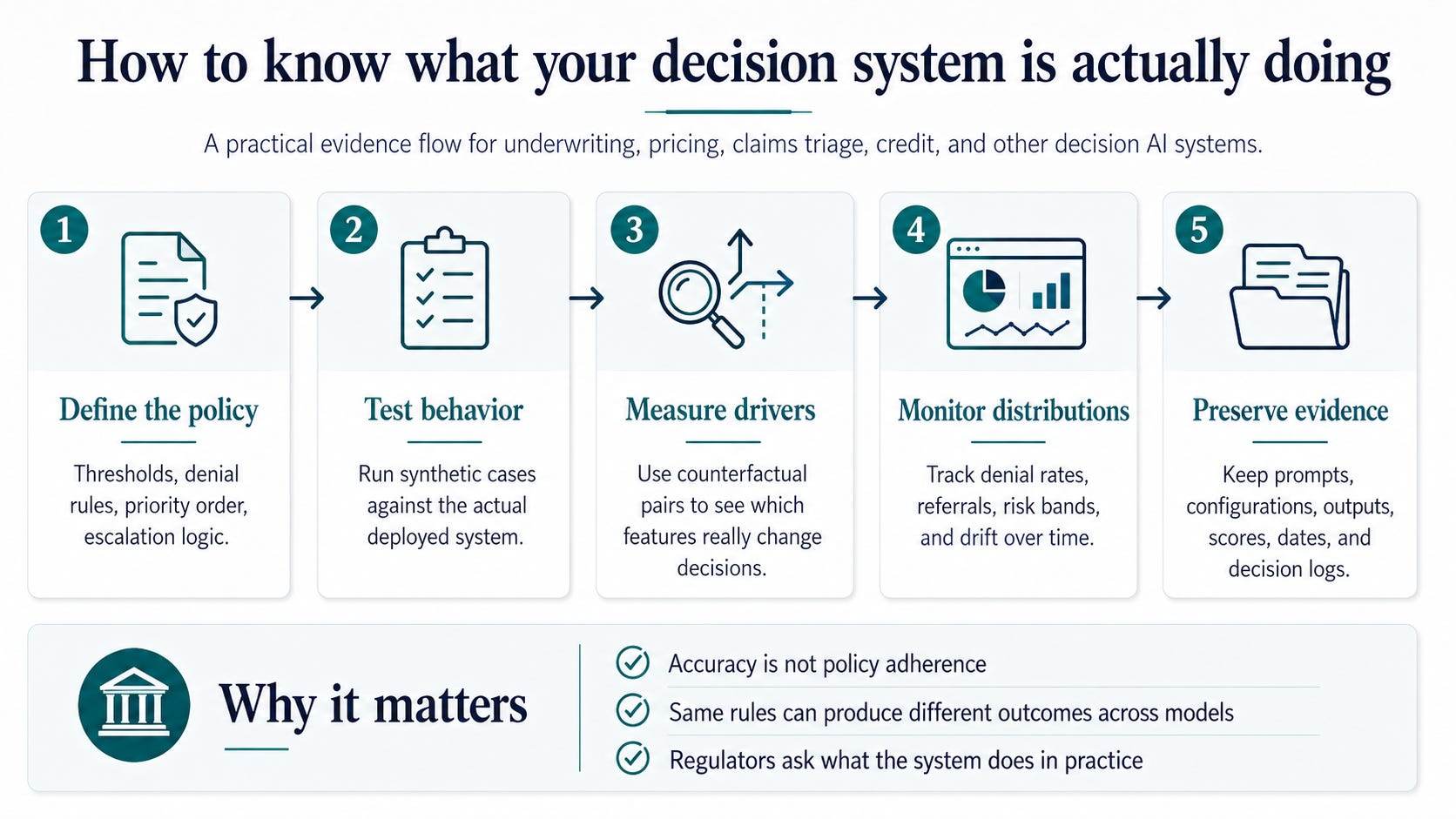
1. Test model behavior against your actual policy before deployment.
Not accuracy benchmarks.
Not general capability evaluations.
Structured testing that asks:
Does this model follow our specific rules?
If your underwriting policy says deny above a threshold, verify that the model denies above that threshold.
It sounds obvious.
Almost nobody does it.
2. Treat model selection as a governance decision.
Different models interpret the same instructions differently.
That is not a bug to fix. It is a characteristic to measure and manage.
The choice between Model A and Model B is not just about performance or cost. It is about how your policy gets enforced.
That decision should be documented, justified, and reviewed.
3. Monitor decision distributions over time.
A model that follows your policy today may not follow it after an update, a configuration change, or a shift in the data distribution.
If your deny rate suddenly drops from 18% to 2% and nobody noticed, you have a policy enforcement gap running in production.
Continuous monitoring is not optional under Article 72. Providers of high-risk systems are required to monitor operation and report serious incidents, and deployers need operational evidence that allows them to detect when the system is no longer behaving as expected.
But even without the regulation, a silent shift in your denial rate is a business risk that no compliance framework can excuse.
4. Build the evidence package before you need it.
Regulators, auditors, boards, and courts do not want to hear that your model “probably” follows your policy.
They want evidence.
Structured, reproducible, documented evidence of what the system actually does under defined conditions.
Building that evidence after an incident is too late.
Our Method
Full methodology is available in the technical appendix. The summary:
Synthetic data only. No real applicants, no real insurers, no real underwriting systems. All profiles were generated with fixed seeds for reproducibility.
Frozen configurations. Prompt hashed before and after each run. Model settings locked. No mid-run changes.
Counterfactual pairs. 150 pairs — identical applicants differing on exactly one attribute. Change one input, hold everything else constant, measure whether the decision changes. This is how you identify what actually drives a model’s decisions, as opposed to what the prompt tells it should.
Policy-adherence scoring. Every decision compared against what the rubric explicitly requires. Clear denominators — every metric reports what it measured and against what population.
Bounded claims. We report what we observed. Not what it “means” for fairness. Not what it “means” for compliance. Behavioral observations, not legal conclusions.
Every finding in this article is a behavioral observation, not a legal conclusion. The distinction matters, and we maintain it throughout.
What This Does NOT Prove
We are explicit about this, and we are not hedging.
This evaluation does not prove any model is biased, unfair, or non-compliant.
It does not constitute legal advice or regulatory assessment.
It does not evaluate any real insurer’s production system.
It does not certify any model as safe or ready to deploy.
The synthetic rubric is not a real underwriting policy.
What it does demonstrate is narrower and still useful:
Structured, reproducible evaluation can reveal the gap between stated policy and actual model behavior.
That gap is measurable.
And the evidence is useful for governance, audit preparation, and model risk management.
But it is not a substitute for legal counsel or regulatory compliance work.
About AiValuations
AiValuations generates structured evidence about AI system behavior for legal, risk, data, compliance, and governance teams.
We do not certify.
We do not audit in the regulatory sense.
We do not tell you whether your system is compliant.
We produce evidence:
What the AI system did.
What controls were tested.
What features appear to drive decisions.
What the gap looks like between your stated policy and your system’s observed behavior.
Your counsel interprets what that means.
Your governance team decides what to do about it.
Track A evaluates language systems — chatbots, copilots, assistants, and RAG workflows.
What does your AI say under pressure?
Track B evaluates decision systems — underwriting, pricing, claims triage, hiring, scoring, routing, and ranking.
What does your AI decide, and is it following the rules you gave it?
We believe the best evidence is the kind that does not need a sales pitch.
This article is based on synthetic evaluation data. No real applicants, insurers, or underwriting systems were evaluated. Results are specific to the tested models under the tested conditions and may not generalize to other models, configurations, or real-world deployments. This is not legal advice. Organizations should consult qualified counsel for compliance decisions.
For methodology details or to discuss how structured evaluation applies to your AI systems — www.AiValuations.org
 | A guest post by
|
Interesting read! The distinction between models getting better at surface-level policy compliance versus still finding sophisticated ways to override or reinterpret the intent felt particularly sharp. It’s making me reconsider some assumptions as I scope a small hackathon project. Thanks for writing it.
This is frontier thinking. Thanks!